
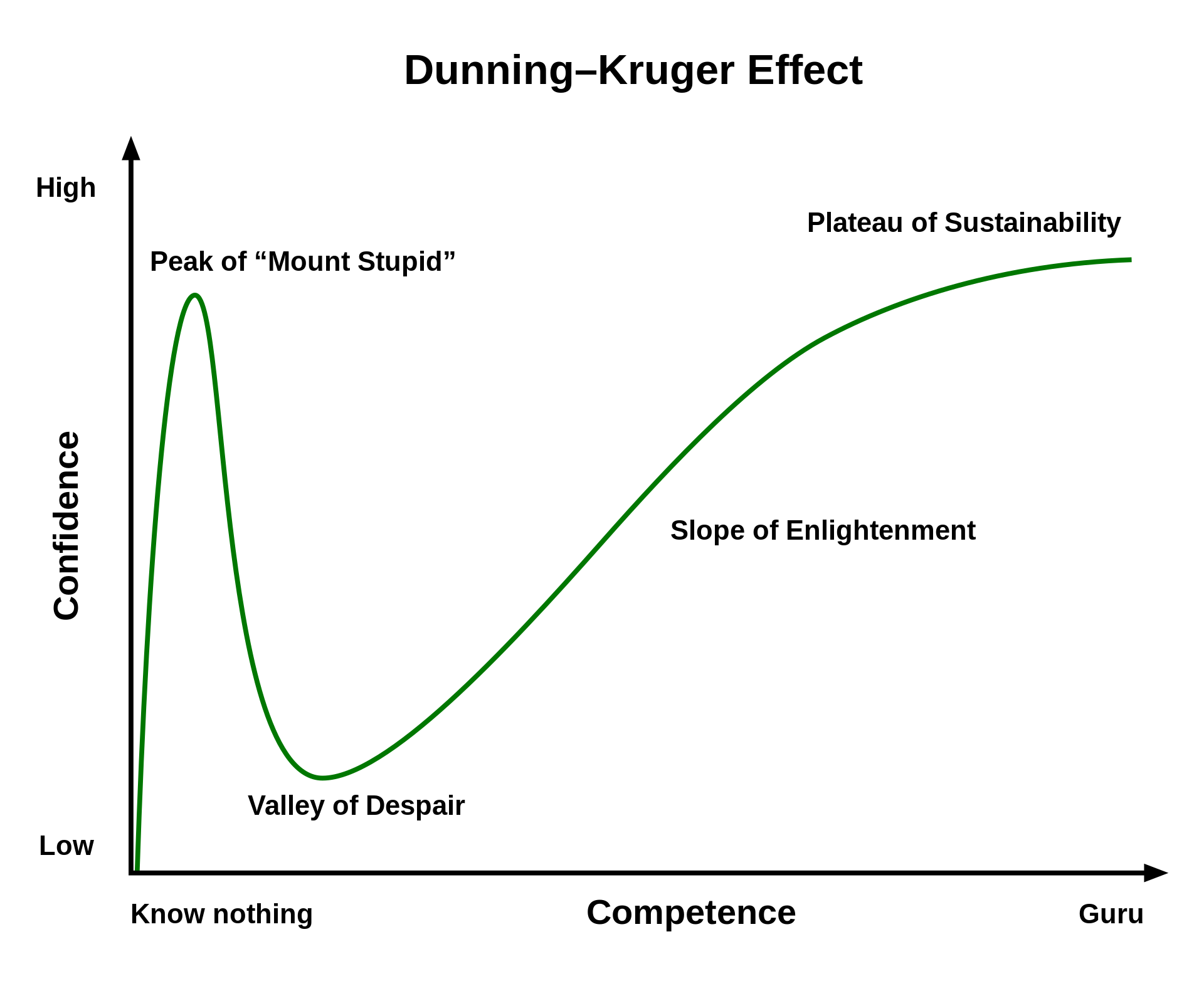
The Dunning-Kruger effect describes a cognitive bias where people with limited knowledge in a domain overestimate their own competence. It was identified in 1999.
Dunning-Kruger effect
Chasing perfection
There is a particular kind of caution that comes with doing things well. In the 2015/16 NBA season, the Golden State Warriors finished 73-9 — the best regular season record in league history. They lost the Finals to the Cleveland Cavaliers. In the 2018/19 Premier League season, Liverpool accumulated 97 points — a record for a runner-up — and still lost the title to Manchester City by a single point.
The best teams in the world, at their best, still lost. Not because they weren't good enough, but because perfection is a moving target and the margin for error at the top is razor thin.
Good developers either understand this intuitively, or were humbled enough in the past to know it by now.
Shipping code vs shipping software
Perfectly written code can still fail. Deployments break for reasons outside anyone's control — environment mismatches, infrastructure issues, edge cases that only appear in production. Competence is not measured by whether things break, but by what happens next.
With the rise of publicly available LLMs, it has never been easier to push large volumes of generated code on a daily basis. Developers who understand software tend to be cautious about introducing new complexity — especially when that complexity might be unnecessary. That caution can look like underperformance to someone who doesn't know what they're looking at. Meanwhile, a junior pushing hundreds of lines of LLM-generated code daily can look like a productivity machine — until something breaks and nobody understands why.
And then there's a third group: people outside of development who spend their evenings vibe coding an application and arrive at work convinced they've built the solution to every problem the company has ever had.
LLMs as a tool
LLMs are an irreplaceable tool — especially when used by someone who understands the problem and can provide meaningful context. The output is only as good as the conversation behind it.
I also understand human nature. The need to feel relevant, to contribute, to appear bigger than you are. I understand the excitement of running something locally for the first time and watching it work — we all went through that when we were starting out. That enthusiasm is not the problem.
The problem is when that enthusiasm becomes a substitute for curiosity. When you stop asking questions because the model is answering them — or so it seems. Will this scale? What happens when this hits production on a Friday evening? Who owns this when it breaks? Is this feature solving a real problem or just adding surface area for bugs?
These are not pessimistic questions — they are the questions that separate someone who ships software from someone who ships code.
Someone who doesn't understand the problem can't provide that context. The model responds confidently regardless. The code looks right. It might even work — until it doesn't.
Mirror on the wall
AI is an irreplaceable tool when you have a problem you understand and want to solve. When you rely on it for something you don't understand yourself, you sound competent — until the first build fails at deploy.
That's where the Dunning-Kruger curve reasserts itself. Loudly.